Gremlin, the leading Chaos Engineering platform helping companies improve resilience and reduce downtime, today announces Automatic Service Discovery at FailoverConf. The new feature from Gremlin automatically identifies the various services running across distributed systems, which enables engineers to directly target them for more effective Chaos Engineering experiments.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20210427005023/en/
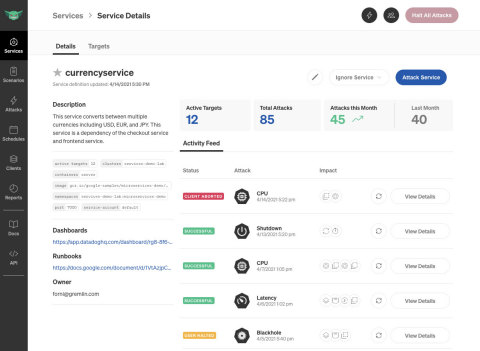
Track reliability progress over time. (Graphic: Business Wire)
“When we started Gremlin our primary focus was on the underlying infrastructure, helping customers answer questions like, ‘Can we handle server crashes?’ or ‘Can this cluster deal with a 10X traffic spike?’” said Matthew Fornaciari, CTO and Co-Founder of Gremlin. “But the rise in popularity of microservices necessitate services functioning as first-class citizens. The infrastructure layer is becoming more abstract and engineers are increasingly thinking about their systems as a collection of services. We want to replicate that mental model in Gremlin and reduce the cognitive load necessary to create controlled chaos.”
Gremlin’s Automatic Service Discovery works by identifying the services running where the Gremlin agent is installed, and then surfacing the operational data that makes those services function, such as process names, container images, and where the service is deployed. This makes it easier than ever before for engineers to run targeted chaos experiments, regardless of how they are hosted, be it distributed across hosts, containers, or even multiple cloud providers.
“End customers won’t care about the ephemeral workloads and API calls happening behind the UI, they just want applications that function and perform as expected,” said Jason English, Principal Analyst at Intellyx. “Before DevOps teams can shift-left and engineer resiliency into a system with early performance testing, chaos experiments and telemetry; they need to shift-right and discover exactly what services are contributing to that customer experience in production.”
Gremlin has also built a new way to track reliability progress, enabling SREs and DevOps teams to click into a particular service and view the full history of experiments run over time. The owner of the service can also include links to runbooks for remediation and any associated dashboards for deeper observability. Having a single view for all of this information will provide engineers with a greater understanding of the reliability of their services.
More resources
Read the State of Chaos Engineering 2020 report: gremlin.com/state-of-ce/2021
Get started with Gremlin: gremlin.com/get-started
RSVP for FailoverConf: failoverconf.io
About Gremlin
Gremlin is the world’s first hosted Chaos Engineering service with a mission to help build a more reliable internet. It turns failure into resilience by offering engineers tooling to safely experiment on complex systems, in order to identify weaknesses before they impact customers and cause revenue loss. Investors include Amplify Partners, Index Ventures, and Redpoint VC. Key customers include GrubHub, HEB, JPMorgan, Mailchimp, Target, Twilio, Under Armour, and Walmart.

View source version on businesswire.com: https://www.businesswire.com/news/home/20210427005023/en/